Building a Self-Sustaining Efficiency Engine: A Step-by-Step Guide to Meta's AI-Powered Capacity Optimization
Introduction
At Meta, serving over 3 billion people means that even a 0.1% performance regression can consume massive amounts of power. The Capacity Efficiency Program tackles this challenge through a two-sided approach: offense (proactively finding and fixing inefficiencies) and defense (rapidly detecting and mitigating regressions). By building a unified AI agent platform, Meta has automated both sides, recovering hundreds of megawatts of power and freeing engineers from manual performance tuning. This guide walks through the key steps to implement a similar self-sustaining efficiency engine, leveraging AI to scale without proportionally growing headcount.

What You Need
- Domain Expertise: Senior efficiency engineers who know the ins and outs of your infrastructure.
- Unified Tool Interface: A standardized platform for AI agents to interact with your systems.
- Regression Detection System: A tool like Meta's FBDetect that catches regressions in real-time.
- AI Agent Platform: A framework for building reusable, composable AI agents that automate investigation and resolution.
- Pull Request (PR) Automation: Systems that can generate and submit PRs for efficiency improvements.
- Monitoring Infrastructure: Metrics and logs to track resource usage and power consumption.
Step-by-Step Guide
Step 1: Establish Offense and Defense Strategies
Start by defining your two core pillars—offense and defense. Offense focuses on proactive code changes that improve efficiency (e.g., algorithm optimizations, resource reduction). Defense involves monitoring production systems to catch regressions caused by new deployments. Ensure both pillars are measured with clear key performance indicators, such as megawatts saved (offense) and regression response time (defense).
Step 2: Build a Unified AI Agent Platform
Create a centralized platform where AI agents can access standardized tool interfaces. This platform should encode domain expertise from your senior engineers into reusable skills—small, composable modules that handle specific tasks (e.g., profiling a service, identifying inefficiencies). Each agent can then orchestrate these skills to automate investigation workflows. The platform must be extensible, allowing new skills to be added as your infrastructure evolves.
Step 3: Encode Domain Expertise into Reusable Skills
Work with your most experienced engineers to document common efficiency patterns—both for offense (e.g., memory leaks, unnecessary computations) and defense (e.g., sudden CPU spikes). Turn these patterns into AI agent skills that can automatically detect and diagnose issues. For example, a skill might analyze a regression signal, correlate it with recent code changes, and propose a root cause. By reusing these skills across agents, you multiply their value without requiring new training data.
Step 4: Automate Regression Detection and Mitigation
Deploy a system like FBDetect to continuously monitor resource usage across your fleet. When a regression is detected, the AI agents kick in: they investigate the anomaly, trace it to a specific pull request, and either automatically roll back the change or generate a fix. This reduces manual investigation from ~10 hours to ~30 minutes, and faster resolution means fewer wasted megawatts compounding across the fleet. Set up automated alerts and dashboards to track performance of this defense loop.
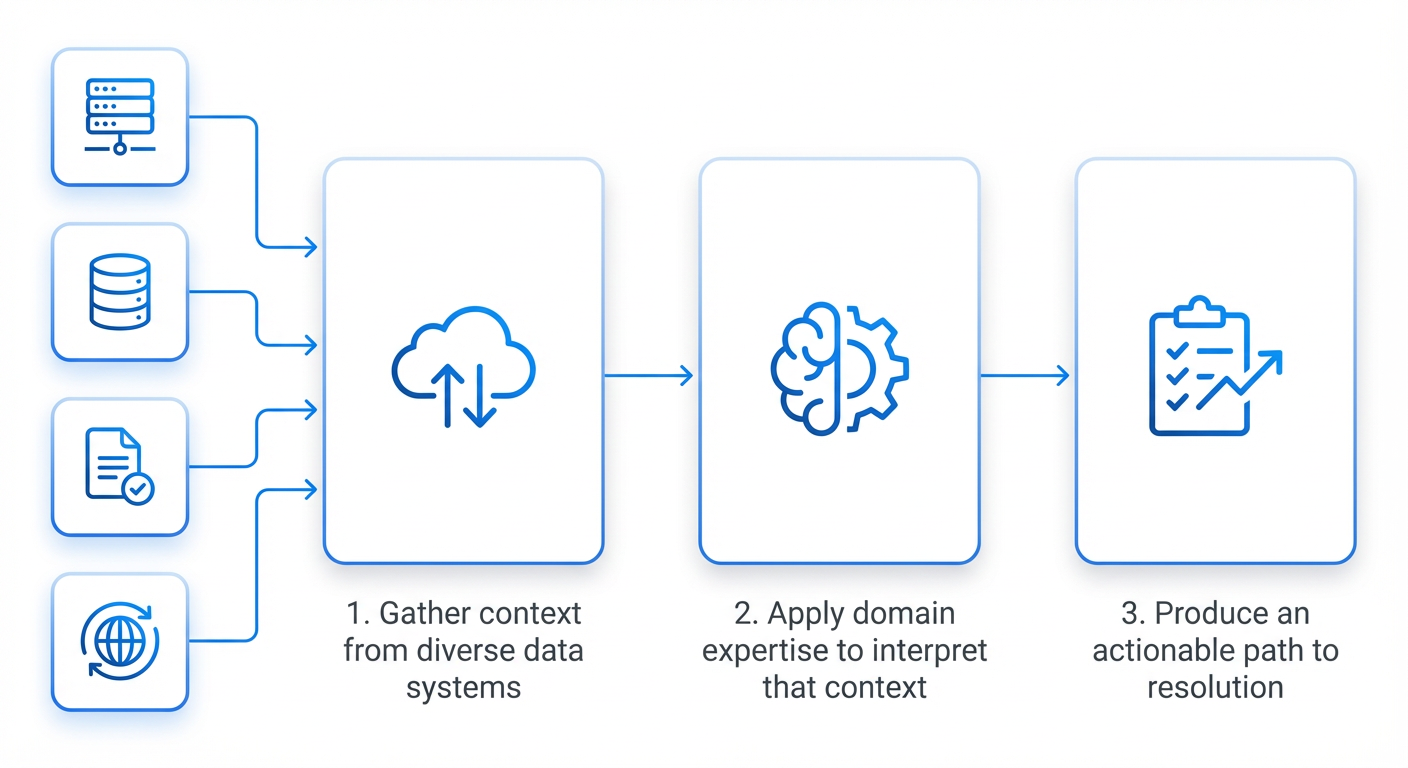
Step 5: Scale AI-Assisted Opportunity Resolution
For the offense side, use AI agents to proactively scan your codebase and infrastructure for efficiency opportunities. The agents generate automated pull requests with suggested optimizations, complete with before/after benchmarks. Engineers then review and approve these PRs, dramatically increasing the volume of wins. As the system matures, expand it to more product areas each half-year, handling a growing backlog that humans alone could never address.
Step 6: Aim for a Self-Sustaining Engine
The end goal is to create a flywheel where AI handles the long tail of efficiency improvements. Continuously feed back successful fixes into the skill library, so the system gets smarter over time. Monitor the ratio of AI-automated vs. human-initiated efficiency gains. With enough domain expertise encoded and a robust platform, the program can deliver megawatt savings without proportionally growing the team—freeing engineers to innovate on new products rather than firefighting performance issues.
Tips for Success
- Start small, iterate fast: Begin with a single product area and one or two AI agents before scaling to the entire fleet.
- Invest in data quality: Accurate monitoring and clean historical data are crucial for training and validating your AI agents.
- Ensure human oversight: Always have a review step for AI-generated pull requests to avoid unintended side effects.
- Promote reuse: Design skills to be as generic as possible—this reduces duplication and speeds up expansion.
- Measure what matters: Track not just power savings, but also time saved for engineers and regression resolution speed.
- Foster a culture of efficiency: Encourage all teams to contribute domain expertise to the agent platform, turning efficiency into a shared responsibility.
By following these steps, you can build a capacity efficiency program that leverages AI to optimize performance at any scale—just as Meta has done. The result is a self-sustaining engine that continuously automates both offense and defense, driving massive power savings while allowing your talent to focus on innovation.